
Reliable OR development. Testing with Hypothesis
07 Feb 2021 | | or budget testing hypothesis property-based testing optimization knapsackSometimes you start with a simple optimization model, and then you are asked to add more and more features and constraints. Sometimes you venture into complicated modeling from the very beginning when it is not always even clear how different constraints will interact with each other.
But in any case, you want to make sure that your model is correct, that your solution satisfies customer requirements with any valid data input. How? Obviously by testing it. However usual unit-testing approach will most likely fail here.
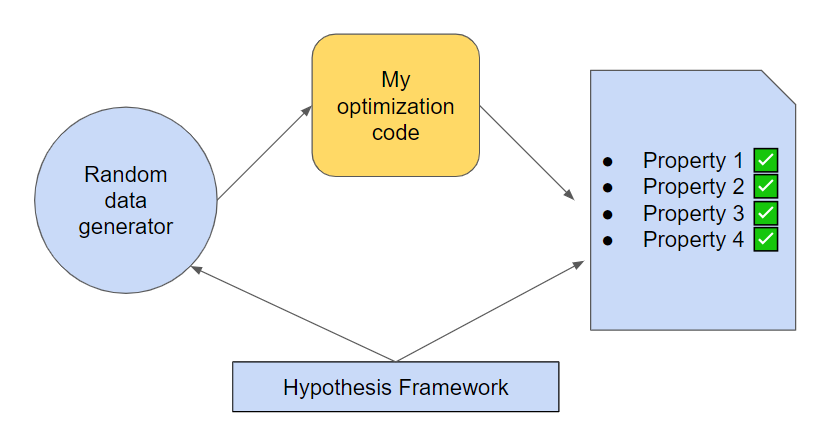
In this article, we talk about an efficient and simple way to test optimization models, which was introduced to me by my colleague Torsten. More specifically, I will talk about the Hypothesis framework which can be used for any type of code, and exceptionally well fits Operations Research testing needs. Let’s start!
What can be challenging with the usual testing approaches?
The usual setup for most of the OR projects is to use a 3rd party optimization software: commercial (Gurobi, CPLEX, etc.) or open-source (CBC, SCIP) solver. We rely a lot on this software to be well tested and maintained, but it is not always the case. But for the model we are using in production we want to be sure!
What our code generates in this setup? Usually, our code gets input data and creates a complex model object (either with wrapper APIs like PuLP or OR-tools or directly with solver API). This model object is transferred to the solver software, which in turn tries to generate a solution corresponding to the model as well as some additional metadata (e.g. whether it was solved optimally, what is the MIP gap, etc.).
So what do we test in such a system?

If we want to do unit-tests by book, we would then look only in the object directly generated by our code: the model object. We can test whether a specific constraint was added, how many variables it contains, type of variables, etc. But it does not give us any guarantee that our code is production-ready.
It may make more sense to do integration tests, which will also incorporate black-box solver output. What we can do is to generate several data examples, generate code with our model, run the solver on it and verify if the resulting solution looks good. However one should manually create these data instances (can amount to a large testing code base for all model features), potentially think about the edge cases and make sure that we tested all the necessary model requirements.
What we will discuss in this post, is property-based testing approach, which can be used for both unit and integration tests. The main idea is to use a framework, which allows generating random instances of the data for our code, and then we test several properties of the code output. Let’s see how.
Is my knapsack overweighted?
Let’s do classics: the Knapsack problem. As before, we will use PuLP because it simple and comes with an open-source solver CBC on board.
def create_knapsack_problem(
profits: List[float], weights: List[float], capacity: float
):
index = range(len(profits))
model = pulp.LpProblem("knapsack_problem", pulp.constants.LpMaximize)
decision_vars = pulp.LpVariable.dicts("decisions", index, 0, 1, pulp.LpInteger)
objective = pulp.lpSum([decision_vars[t] * profits[t] for t in index])
model += objective
capacity_constraint = (
pulp.lpSum([decision_vars[t] * weights[t] for t in index]) <= capacity
)
model += capacity_constraint
return model, decision_vars
This method gets profits and weights information per item, capacity restrictions, and returns the generated model object together with reference on decision variables (so we can easily parse their values later).
Hypothesis-based testing
So what the Hypothesis framework actually can do for us? It will generate a sequence of challenges (problem instances) with a sole purpose to break our code. It will try various edge cases for input data, and then will execute our test with a specific property we wish to assert. If the property is not satisfied, we have a breaking instance, and Hypothesis framework will report an annotation string to reproduce this problem. Even more, when property is falsified, Hypothesis will try to generate a shrinked example, which is still failing the test, which is by itself an amaizing feature. It allows to easier reason about failure reason, and definitely useful when you debug a large model.
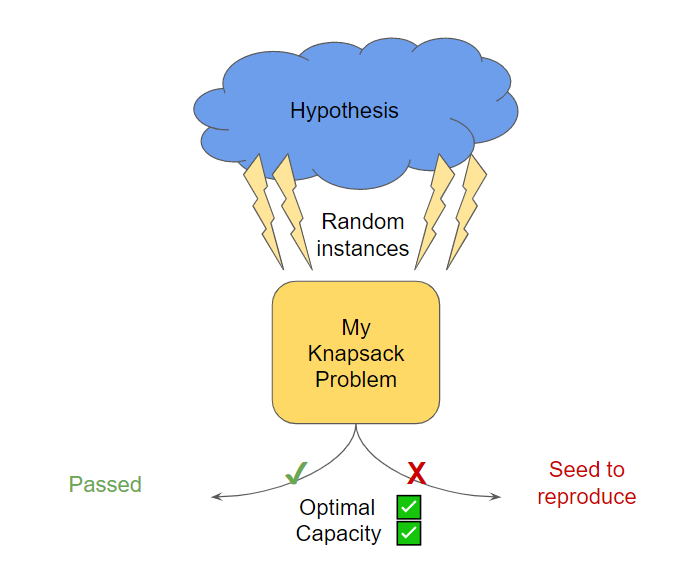
We start with desired properties of the solution. What do we expect from the Knapsack problem outcome? If the inputs are valid (non-negative values), then we do expect every problem to be solved optimally (except large instances, which may be interrupted).
Another obvious property is that the total weight of the knapsack should not be larger than the capacity of the knapsack, which is literally the main constraint of the problem.
Data generation
We need to explain the Hypothesis framework how to generate test instances. This is another crucial part of property-based testing.
The inputs for our method are:
- profits array (length is equal to the number of items), which contains non-negative values
- weights array, also non-negative values
- capacity, a positive number
import hypothesis.strategies as st
@st.composite
def profits(draw, length):
return draw(
st.lists(
st.floats(min_value=0, max_value=50.0), min_size=length, max_size=length
)
)
What we say here is that we want a profits array of a specific length, which contains values from 0 to 50 of type floats. Similarly, we define a method for the generation of weights array. And we wrap it all up in a single method:
@st.composite
def generate_data(draw, length=20):
profits_data = draw(profits(length))
weights_data = draw(weights(length))
return profits_data, weights_data
Testing
Now we are ready for writing all our tests! Let’s start with the first desired feature: all small problem instances should be solved optimally. We first specify parameters, necessary for data generation:
@given(generate_data(length=20))
Here we ask to generate problem instances with 20 items. It is often to specify additional metadata for the Hypothesis framework, which governs tests execution:
@settings(max_examples=8, print_blob=True, deadline=timedelta(seconds=20))
And here we say that we want 8 examples to be generated, “print_blob” allows to printout data necessary for tests reproduction (we will see used it later) and finally we set a deadline in order not to have a very long-running test.
As for the test body, it remains pretty straightforward. We create model, solve it and assert if the status is optimal:
def test_knapsack_model_optimal(data):
profits, weights, _ = data
model, _ = create_knapsack_problem(profits, weights, 10)
status = model.solve()
assert LpStatus[status] == "Optimal", "Al small problem instances should be optimal"
So what Hypothesis framework will do for us here? It will generate in a smart way 8 examples from specified data distribution and verify if our desired property is true. What does it mean “in a smart way”? That means that the framework already contains a logic to test edge cases in the data, e.g. zeros and min/max values, which have a higher chance to break your code. You execute as usual with pytest and it.. works!
Reproducing failing examples
But not all tests will always work. Hypothesis framework uses random seed, so everytime you execute the test, data instance can be different. How do we debug such thing?
Let us write a new test for the second desired property, i.e. for the capacity of the Knapsack. It looks pretty similar to the test above, but we in addition need to sum up all the weights of selected items:
def test_knapsack_model_respects_capacity(data):
profits, weights, _ = data
index = range(len(profits))
capacity = 10
model, decision_vars = create_knapsack_problem(profits, weights, capacity)
status = model.solve()
solution = [
decision_vars[t].varValue if decision_vars[t].varValue is not None else 0
for t in index
]
total_weight = sum([solution[t] * weights[t] for t in index])
assert total_weight <= capacity, "We should not overweight our knapsack!"
But what will happen if the test fails? Let’s cheat, and instead of breaking our code, we break our test. We substitute the valid check in the last line of the test, with an erratic one, purely for demonstration purposes:
assert total_weight <= 0, "We should not overweight our knapsack!"
The first thing we notice is that now the test takes much longer. This is because the Hypothesis tries to find a minimal breaking example for your code (you can turn off such behavior). When it finally fails, you would see an important log message:
You can reproduce .. @reproduce_failure('4.51.1', b'AXicY2CgGHQWJFBuCBAwIpgAb0wBWw==')
FAILED test/hypothesis_testing/model/test_knapsack_model.py::test_knapsack_model_respects_capacity - AssertionError: We should not overweight
Bingo! If you copy the “reproduce_failure” annotation and add it to your test, then on every execution of it Hypothesis will generate exactly one example which was breaking it. Now you can easily debug and fix your code, given the property-breaking data instance.
Final notes
I love the Hypothesis framework because it makes testing optimization models easier and more intuitive. Once I have defined data generation patterns for my model, I just quickly make a property-based test for each feature/constraint which I want to verify. Then I can run it locally with a large number of examples, and when I am convinced that the code is working, I reduce the number of examples and deadlines to something reasonable to not overload CI/CD pipelines.
The obvious benefits for me are thus:
- Quick and easy integration testing
- Concise tests (when data generation is extracted)
- Possibility to try many different instances through simple parametrizations
Given all this I would still not advocate using Hypothesis tests alone: edge cases there are generic, and do not take into account the specific structure of your code. Thus it may just not be able to catch code-breaking examples. However, I believe the property-based testing is a wonderful addition to classical unit and integration tests and allows to make reliable OR projects and will keep your Knapsack fit.
Code
This code can be found in repository